แปลงเสียงและวิดีโอเป็นข้อความ
AI ถอดเสียง-แยกผู้พูด-สรุปเนื้อหา-โหลดไฟล์ ให้คุณไม่พลาดทุกประเด็นสำคัญ
ถอดไฟล์เสียง ไฟล์วิดีโอ ลิงค์วิดีโอ และบันทึกเสียงสด
ถอดเสียงและแปลภาษาได้ 99 ภาษา
ทดลองใช้งานฟรีวันละ 2 ไฟล์
ลูกค้าของเรา





















































Your Smart Audio to Text Workspace
AI-powered transcription for audio and video that is simple, private, and built for productivity.
Speech to Text Model
Speech to Text Model (STT) or Automatic Speech Recognition (ASR) is a high-quality AI capable of transcribing speech into text along with time-stamped segments. You can also go back and edit the transcript and timing later for greater accuracy.






One tool for many Roles
Students, researchers, and educators
Transcribe lessons, interviews, and focus group in Thai and other languages.

Government officers
Transcribe mp3, mp4 meetings and summarize official reports and agendas.

Translators
Transcribe, translate, and edit seamlessly in one place.

Corporate teams
Transcribe online meetings with international clients and partners.

Content Creators / Creatives
Transcribe and create SRT subtitles for video editing.

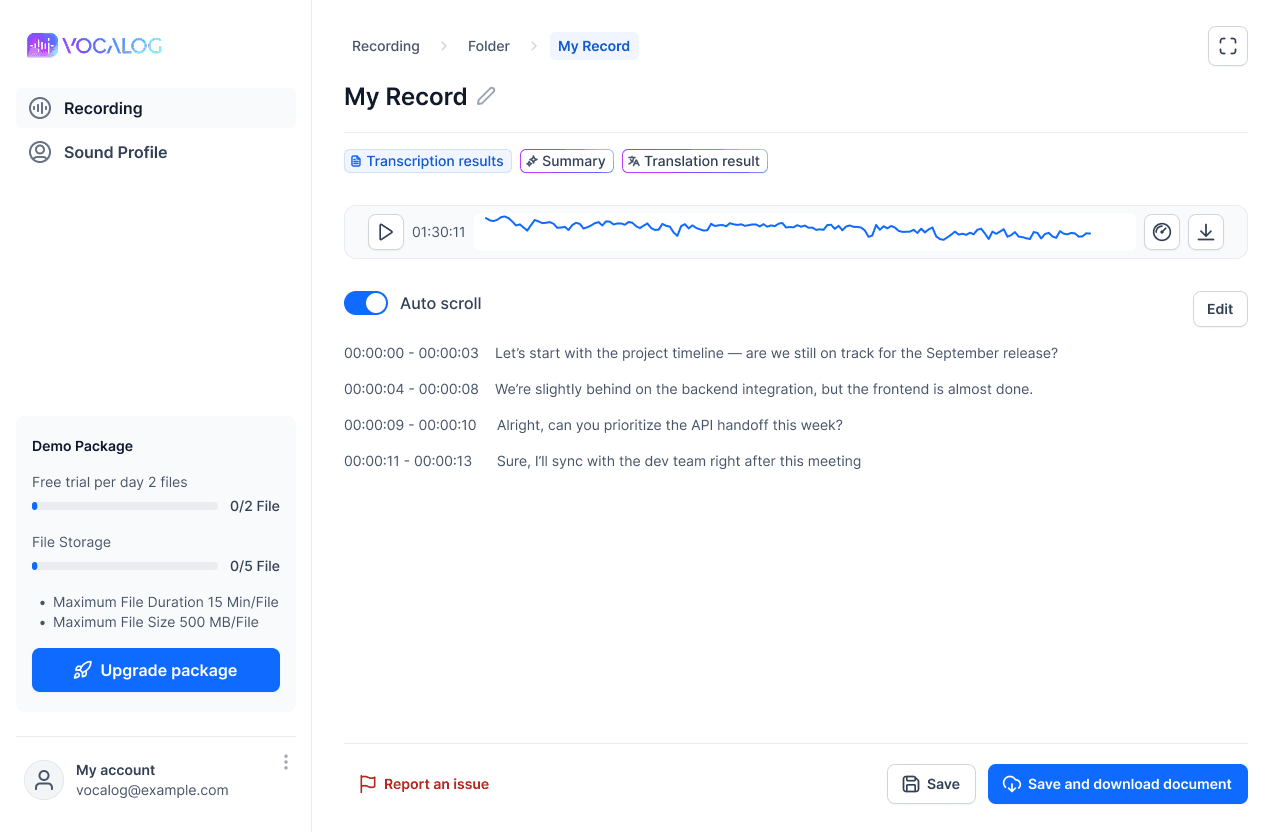
เริ่มต้นใช้งาน Vocalog
ถอดเสียงเป็นข้อความง่าย ใช้งานได้ทั้งไฟล์เสียง และไฟล์วิดีโอ
1

กดสร้างโฟลเดอร์สำหรับเก็บไฟล์เสียงแต่ละโปรเจกต์
2

กดสร้างบันทึกเสียง ตั้งชื่อ เลือกระบุเสียงผู้พูด (หรือไม่ระบุก็ได้)
3

อัปโหลดไฟล์เสียง หรือเปิดไมค์บันทึกเสียง
4

รีวิวข้อความ ช่วงเวลาของเสียง และผู้พูด
5

กดบันทึกและดาวน์โหลดข้อความตามไฟล์ที่ต้องการ
บทความจาก VISAI



Things to Know Before Using Vocalog
To help you get the best experience with Vocalog, please read the following information carefully.
Supported File Types
Transcription Time
Foreign Language Support
Package Pricing
Subscription and Renewal
If Transcription Fails
Data Privacy and Security

บริษัท วิสัย เอไอ จำกัด (สำนักงานสาขากรุงเทพฯ)
อาคาร Digital Startup Building
1284, 1286, 1288, 1290 ถนนลาดพร้าว
แขวงจอมพล เขตจตุจักร กรุงเทพมหานคร 10900
ได้รับการรับรองมาตรฐาน
